

So you implemented zero-touch deployment last year. The vendor demo was slick. The ROI calculator showed you'd save 40 hours per month. Your IT director was thrilled to finally stop unboxing laptops.
And now? Your team is somehow busier than before.
They're not imaging devices anymore, sure. Instead, they're maintaining this sprawling maze of policies and exceptions. They're debugging why MacBooks in certain regions won't enroll. They're fielding Slack messages at midnight from new hires whose laptops arrived but won't connect to anything.
The manual work disappeared. The actual work just shifted, and probably got harder. Nobody warned you about that part.
TL;DR
- Zero touch deployment eliminates manual IT intervention during device setup, but most implementations still carry hidden labor costs in planning, troubleshooting, and exception handling
- The gap between technical automation and operational reality creates configuration debt that compounds over time
- True ZTD requires designing for failure scenarios and edge cases, not just the standard deployment path
- Security requirements and employee experience often conflict in ZTD setups, creating friction that undermines adoption
- Procurement timing and vendor coordination issues frequently break even well-designed automation workflows
- Removing touch from deployment can inadvertently remove visibility into what's actually happening across your device fleet
- Success depends on integrating logistics, configuration management, and real-time monitoring into a unified system
The Labor You Can't See (And Why It's Eating Your Budget)
So your IT team stopped touching devices. Victory, right?
Except now they're spending entire afternoons mapping out decision trees that would make a computer science professor weep. "If Marketing + California + Adobe CC + full-time = Policy 7B. Unless contractor, then Policy 11A. Unless the contractor is working on the Johnson project, then override with..."
I watched an IT manager at a 300-person company spend six hours one week just documenting why a specific VPN configuration existed. Turns out it was created for one person who left 14 months ago. But nobody wanted to delete it because "what if something breaks?"
This is what replaced imaging laptops. Not nothing, just invisible work that's somehow more exhausting.
You're still paying for device deployment. You're just paying in cognitive load instead of repetitive tasks. And honestly? Cognitive load is more expensive. You can hire a junior tech to image laptops for $50K. The person who can architect and maintain complex MDM policy matrices? That's a six-figure role, minimum.
Understanding what is zero touch deployment requires looking beyond surface-level metrics. Most companies measure ZTD success by counting how many devices ship directly to employees instead of going through IT first. That metric misses the entire story. You've eliminated the visible labor (unboxing, imaging, configuring) while creating invisible labor (policy architecture, exception workflows, post-deployment troubleshooting).
Let me break down where the time actually goes now:
Policy architecture that never stops growing. Every new hire isn't just a new user, they're a new combination of variables. Department, role, location, compliance requirements, device type, employment status. Your MDM needs rules for all of it. We've seen companies with over 200 active policies trying to cover every permutation. Nobody knows what half of them do anymore.
The multi-MDM nightmare. You acquired two companies last year? Congratulations, you now maintain three separate MDM platforms because migrating everything would take six months and nobody has six months. So you're juggling Jamf, Intune, and whatever that startup was using. Each one has different enrollment processes, different policy languages, different breaking points.
Automation scripts that need constant babysitting. That elegant script that handles OS updates and app installations? It breaks every time Apple releases a point update. Or when a critical app changes its installation method. Or when, and this happened to a client, a developer pushed a test build to production and bricked 40 devices overnight.
Exception handling that happens at 2 AM. Your automation works great during business hours in US time zones. But that employee in Singapore who needs their laptop working by morning? Someone's getting woken up to troubleshoot why the enrollment profile won't download over their home internet.
Tribal knowledge that lives in people's heads. Why does the engineering team have a different firewall configuration than everyone else? "Oh, that's because back in 2021 we had this issue with Docker, and Sarah fixed it, but Sarah left last year, so now we're just afraid to change it." Cool, cool. Very sustainable.

The really frustrating part? Some companies are spending more on ZTD than they did on manual provisioning. They hired automation engineers. They licensed orchestration platforms at $15 per device per month. They built custom integrations because their procurement system doesn't talk to their MDM, which doesn't talk to their asset management platform, which doesn't talk to HR.
The promise was efficiency. The reality is you traded simple, repetitive work for complex, high-stakes work. And complex work is harder to hire for, harder to document, and way harder to hand off when someone quits.
I'm not saying ZTD is a mistake. When it's done right, it absolutely scales better than manual provisioning. But "done right" is doing a lot of heavy lifting in that sentence.
What Zero Touch Deployment Actually Means (Beyond the Vendor Pitch)
Okay, definitions. Zero-touch deployment means shipping a laptop straight from the manufacturer to an employee's house, and it just... works. No IT person opens the box. No staging area. No "bring your laptop to the office for setup day."
Employee opens box, turns on device, it automatically knows who they are and what they need. Apps install themselves. Security policies apply. VPN configures. Done.
That's the idea, anyway.
What actually has to happen for this magic trick to work? You need to pre-configure everything before the device ships. And I mean everything:
- MDM enrollment profiles tied to specific device serial numbers
- User assignments (this laptop belongs to Jane in Marketing)
- App catalogs (Jane needs Slack, Figma, and Chrome, but not the developer tools)
- Security baselines (encryption on, firewall configured, password requirements set)
- Network settings (VPN, WiFi, proxy configurations)
All of this has to be set up and ready to go before the laptop leaves the warehouse. When Jane powers it on for the first time, it connects to the internet, checks in with your MDM, sees "oh, I'm Jane's laptop," and pulls down all her stuff automatically.
The technical components that make this possible:
For Apple devices: Automated Device Enrollment (ADE). You register device serial numbers with Apple before they ship. When someone turns on that MacBook, it automatically knows to enroll in your MDM. Works pretty reliably, when the vendor actually registers the devices correctly, which doesn't always happen.
For Windows: Autopilot. Microsoft's version. You pre-register devices in Azure AD and Intune. Similar concept, different ecosystem, different set of things that can go wrong.
MDM platforms: Jamf, Kandji, Intune, etc. These are your remote control centers. They manage configurations, push apps, enforce policies. They're also where you'll spend countless hours troubleshooting why a policy that worked yesterday is failing today.
Identity providers: Azure AD, Okta, Google Workspace. Handle user authentication and app access. When they work, they're invisible. When they don't, say, latency issues in certain regions, your entire enrollment process grinds to a halt.
App deployment catalogs. Pre-approved software that installs silently based on who's using the device. In theory, this is great. In practice, you'll discover that half your apps need manual authentication, license keys, or specific installation sequences that break silent deployment.
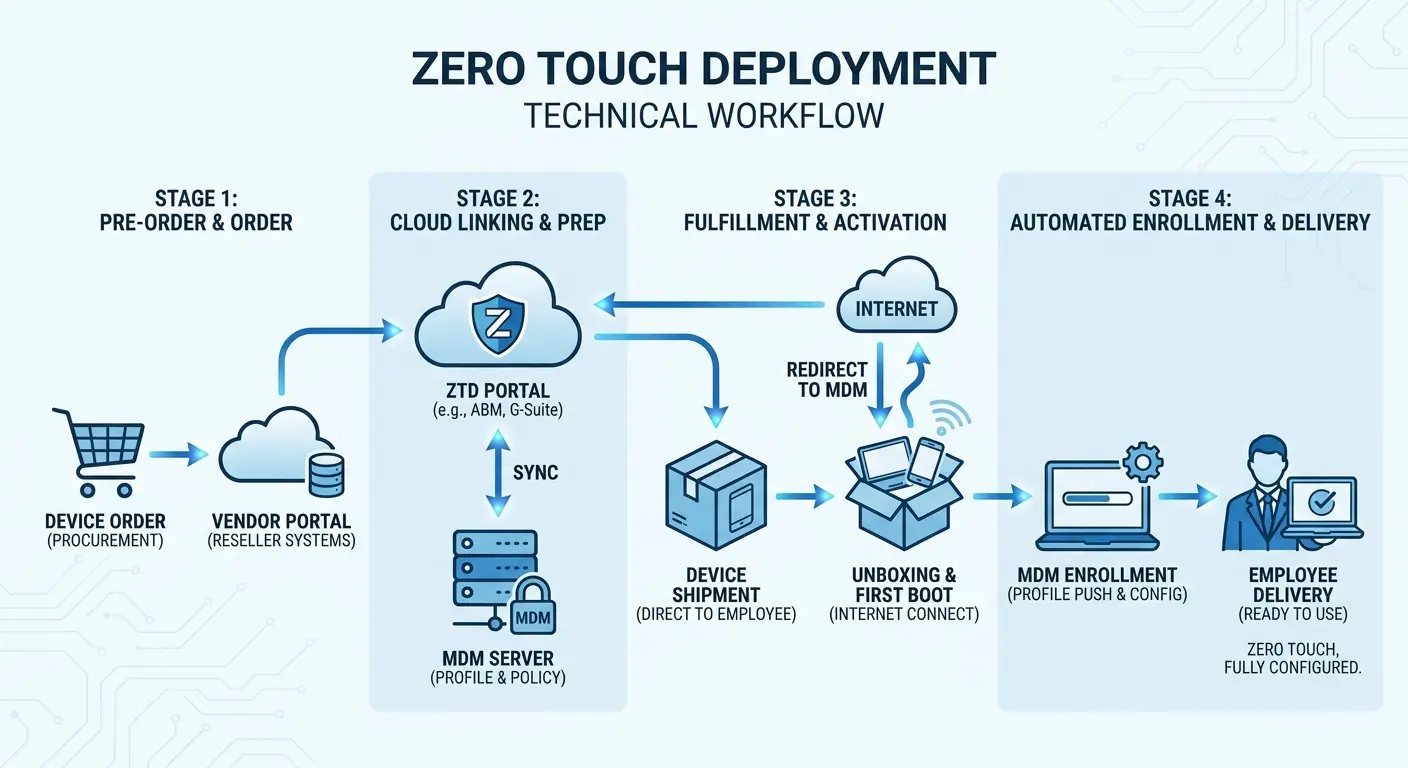
You configure all these systems to work together, and theoretically, every new device follows the same automated path.
Except, and here's where the vendor demos always gloss over reality, you don't configure them once. You configure them constantly.
New department? New configurations. New compliance requirement? Update all the policies. Acquired a company? Now you're supporting their legacy systems too. Hired your first engineer who needs Docker? Congratulations, you just discovered that Docker conflicts with your security agent, and now you need a whole separate policy branch for the engineering team.
| ZTD Component | What It Does | What It Doesn't Do |
|---|---|---|
| Automated Device Enrollment (ADE/Autopilot) | Links device serial numbers to your MDM before shipment; triggers automatic enrollment on first boot | Handle procurement delays; account for vendor registration errors; work with non-supported hardware vendors |
| MDM Platform (Jamf, Intune, Kandji) | Manages remote configuration, policy enforcement, app deployment | Solve policy conflicts; prevent configuration debt; automatically optimize policies over time |
| Identity Provider (Azure AD, Okta) | Authenticates users; controls app access based on role | Adapt to network latency issues; function offline; handle password reset scenarios seamlessly |
| App Deployment Catalog | Installs pre-approved software silently based on user profile | Know which apps users actually need vs. requested; handle license management; update apps that require manual authentication |
| Security Baseline Policies | Enforces encryption, firewall, password requirements automatically | Balance security with user experience; account for role-specific exceptions; prevent legitimate work from being blocked |
The marketing materials show this beautiful linear process: order, ship, auto-setup, done.
Real implementations look like a flowchart designed by someone having a panic attack. Nested if-then statements. Exception handlers. Fallback procedures. "If X and Y but not Z, unless Q, then apply policy set 7B, but override section 3 if..."
And here's what nobody tells you: you need mature processes before automation delivers value. You can't automate chaos. If you don't know which apps your finance team actually needs versus which ones they requested three years ago and forgot about, automation just deploys the wrong stuff faster.
Understanding what is zero touch provisioning requires acknowledging these operational realities. Zero-touch deployment is the end state, not the starting point. Getting there requires you to clean up your device management, standardize your hardware, document your policies, and honestly rethink how you handle IT in general.
Most companies try to automate their existing mess. Then they're surprised when the automation is also a mess.
Why Your "Zero Touch" System Still Needs Constant Touching
Enrollment fails. That's it. That's the answer.
All your automation, all your planning, all those vendor promises, they evaporate the moment an employee in rural Montana tries to download a 47MB MDM profile over 3Mbps internet that keeps dropping.
And suddenly your zero-touch deployment requires a 90-minute Zoom call with IT walking her through manual enrollment. On a Friday evening. When she's supposed to start Monday.
Let me walk you through the greatest hits of ZTD failures I've seen:
Network issues kill everything. Your automation assumes everyone has fast, reliable internet. They don't. I've watched enrollment fail because someone's home WiFi couldn't sustain the connection long enough to download profiles. Or they're in a country where your identity provider has terrible latency. Or their ISP blocks certain ports your MDM uses. Your beautiful automation just sits there spinning, failing, timing out.
Hardware defects that bypass QA. Three to five percent of devices have problems that don't surface until someone actually tries to use them. Dead pixels. Keyboards that miss keystrokes. Batteries that won't hold a charge. These slip through manufacturer quality control, get shipped directly to employees, and now you need reverse logistics, replacement devices, and manual intervention. Your automation can't fix a broken laptop.
Users make mistakes. Shocking, I know. But your automated flow still requires people to select their language, connect to WiFi, and enter their credentials. Non-technical users mess this up in creative ways. They choose the wrong network (guest instead of home). They mistype their password five times and lock their account. They close the setup assistant thinking they can finish later, not realizing it breaks the entire enrollment sequence and now requires IT to manually reset everything.
Real example: Marketing manager, Montana, Friday delivery for Monday start. She unboxes the MacBook, powers it on, automated enrollment begins. The MDM profile is 47MB. Her internet maxes out at 3Mbps with frequent dropouts. Download times out after 12 minutes. She tries again. Same thing.
It's 6 PM Friday. IT support is offline until Monday. She spends her first two work days unable to access email, Slack, or any work tools because enrollment never completed. IT eventually spends 90 minutes on a video call walking her through manual enrollment.
So much for zero-touch.
Policy conflicts that only surface in specific combinations. Your security team requires full disk encryption. Compliance wants audit logging. IT restricts admin rights. Each policy works fine individually. Together, on certain device models or OS versions, they create conflicts. The automation proceeds happily until it hits the conflict, then silently fails, leaving the device in a half-configured state that nobody notices until the user tries to do something that doesn't work.

Time zones and languages break things in weird ways. Your MDM is configured for US English and Eastern Time because that's where your IT team is. Employee in Japan powers on their device, and the enrollment profile doesn't account for Japanese language preference or JST. The device enrolls but with wrong settings. Now someone needs to manually reconfigure everything.
Vendor coordination failures. You ordered 50 laptops. The vendor was supposed to register them in your ADE portal before shipping. They registered 48 and missed two. Those two devices arrive at employee homes and won't auto-enroll. Now you're troubleshooting which serial numbers are missing while employees wait, wondering why their laptop doesn't work.
Or, and this happened to a client last month, the vendor registered the devices in the wrong ADE portal. They have multiple clients and mixed up the accounts. All 50 devices tried to enroll in someone else's MDM. Took three days to untangle.
You can solve some of these with better planning. Network issues? Ship devices early with instructions to contact IT if enrollment fails. Hardware defects? Maintain backup inventory. User errors? Better onboarding documentation.
But some of this is just inherent to supporting diverse users across varied environments with different technical capabilities. You can't QA test every possible home network configuration. You can't predict every way a non-technical user might deviate from your setup instructions.
The companies that succeed with ZTD don't eliminate these touch points. They build faster response systems for handling them. They have backup devices ready. They have support staff who can jump on a call quickly. They set expectations with employees that "zero-touch works 90% of the time, but if you're in the 10%, here's how to get help fast."
Zero-touch is the goal. Zero-friction is what actually matters.
The Configuration Debt That's Quietly Killing You
Every exception you add is a loan against your future IT capacity. And the interest rate is brutal.
You hired a video editor who needs admin rights for plugins. Exception added. Remote team in Germany needs different VPN settings. Exception added. Acquired a startup whose developers refuse to change their workflows. Exception added.
Each one makes sense at the time. Together, they create a policy matrix so complex that no single person understands the whole thing anymore.
I talked to an IT director last month who had 200+ active MDM policies. When I asked him what they all did, he laughed. "Maybe I could tell you what 60 of them do. The rest? No idea. But I'm terrified to delete anything because something might break."
That's configuration debt.
It compounds differently than technical debt in code. You can refactor code over a weekend, run your tests, deploy, done. But MDM policies are actively managing 500 devices across 12 countries right now. You can't just blow it all up and start over. Well, you can, but then you're explaining to your CEO why the London office can't access email.
Policies multiply, but they never die. You create new configurations constantly. New hires, new teams, new compliance requirements. But you almost never remove old ones. That policy for the marketing contractor who left 18 months ago? Still active. Still being evaluated on every device enrollment. Still consuming resources and cluttering your policy list.
Why don't you delete it? Because you're not 100% sure nothing depends on it. Maybe it's referenced by another policy. Maybe someone's device will break. Better safe than sorry, right?
Multiply that decision by 100 policies, and now you're managing a graveyard.
Exceptions become permanent. This is my favorite. You add a "temporary" workaround for a specific situation. It works. You move on. The workaround never gets revisited.
Six months later, someone else hits a similar issue. They don't know about your workaround (because who has time to document everything?). They add their own workaround. Now you have two overlapping exceptions, and nobody knows which one is actually necessary.
Real example from a client: IT admin creates a special MDM policy in March 2022 for a contractor on a three-month project. Contractor needs design software that conflicts with standard security settings. Project ends in June, contractor leaves, policy stays active.
November 2022: Someone troubleshooting a different issue finds this mystery policy. Doesn't know what it does. Leaves it alone because changing unknown things is scary.
March 2024: Company now has 23 orphaned policies like this. Each one processes during enrollment. Each one is a potential conflict point. Zero documentation on any of them.

Documentation always lags reality. You have 200 policies. Your documentation covers maybe 60. The rest live in tribal knowledge, old Slack threads, and Jeff's brain. When Jeff leaves, you inherit a system you can't fully understand without reverse-engineering it.
And reverse-engineering production MDM configurations while devices are actively enrolling? That's a special kind of stress.
Hidden dependencies create fragility. Policy A depends on Policy B, which depends on Configuration C. You change C to fix an unrelated issue. Policy A breaks three weeks later in a way that only affects developers in the EMEA region who use a specific app. Your testing didn't catch it because you didn't know the dependency existed.
Role proliferation spirals out of control. You started with three roles: employee, manager, admin. Clean. Simple.
You now have 47 roles because every team has slightly different needs. Sales uses different apps than Marketing. Engineering needs different security settings than Finance. Remote employees need different VPN configs than office workers. Contractors need restrictions that full-time employees don't.
Each role has its own policy set. Some policies overlap. Some conflict. Some are identical but were created separately because different people managed different onboarding waves and nobody coordinated.
The cost isn't just complexity. It's fragility. Every new device enrollment is a potential failure point because you're running automation through a system with hundreds of undocumented edge cases.
And here's the real problem: you can't A/B test this stuff in production. You can't easily roll back a policy update if it breaks something. You can't refactor your entire MDM setup without potentially disrupting every managed device.
Some companies reach a breaking point where the debt is so high they consider starting over. Fresh MDM instance, clean policies, migrate devices gradually. But you can't do that without risking loss of management for your device fleet, which most companies can't tolerate.
So the debt just keeps accumulating. And the person who understands it best is probably updating their LinkedIn profile right now.
The fix isn't avoiding configuration debt entirely, impossible if you're growing. It's building systems that make debt visible and creating regular cleanup cycles before it becomes unmanageable.
But nobody does that because there's always something more urgent than "clean up old policies." Until the whole thing collapses and cleanup becomes the only thing that matters.
Building for Exceptions (Because the Happy Path Is a Lie)
Most ZTD implementations optimize for the scenario where everything works perfectly.
That's backwards. And kind of delusional.
You should design for the scenario where the employee has never set up a work computer, they're 12 time zones away from your IT team, their internet is garbage, and they need to be productive tomorrow because they're presenting to a client.
That's your actual design constraint. If your system works in that scenario, it'll work everywhere. If it only works when conditions are perfect, you've built something that fails constantly in the real world.
Graceful degradation over binary success/failure. If full automation fails, what's the minimal manual process that still gets someone working? Can they at least access email and Slack while IT troubleshoots the complete configuration?
Your system needs fallback modes. Not just "enrollment succeeded" or "enrollment failed," that's useless. You need "enrollment partially completed, user has basic access, these three things still need manual intervention."
I've seen companies where enrollment failure means the employee is completely locked out until IT fixes everything. That's insane. Build partial success states.
Error messages for actual humans. "Enrollment failed" tells someone nothing useful. They're staring at their new laptop, supposed to start work, and they get a cryptic error. Great.
Try this instead: "Your device couldn't download the security profile. Check that you're connected to WiFi and try again. If this message persists, contact IT at [email] with error code MDM-403-ADE."
Actionable information for the user. Diagnostic data for IT. Both parties can actually do something instead of just panicking.
Self-service troubleshooting before tickets. Build a knowledge base that addresses the top 10 enrollment issues with step-by-step fixes. Most problems, wrong WiFi network, mistyped password, skipped setup steps, don't require IT intervention if you give users clear guidance.
We've seen ticket volume drop 40% when companies actually invest in good self-service documentation. But most companies treat documentation as an afterthought. They write it once, never update it, and wonder why nobody uses it.
Pre-Deployment Exception Planning Checklist
Before rolling out ZTD to your next cohort of employees, validate that you've addressed these common failure scenarios:
- ☐ Fallback enrollment method documented for employees with poor internet connectivity (offline enrollment package, alternative lighter-weight profile, or IT-assisted manual process)
- ☐ Error messages rewritten in plain language with specific troubleshooting steps and unique error codes for IT tracking
- ☐ Knowledge base articles created for the 10 most common enrollment issues based on historical ticket data
- ☐ Support availability mapped against employee time zones with clear escalation criteria for after-hours issues
- ☐ Backup device inventory maintained for hardware defects discovered post-delivery (minimum 5% of quarterly deployment volume)
- ☐ Validation script scheduled to run 24 hours post-enrollment checking for configuration completeness
- ☐ User feedback survey automated to deploy 72 hours after device delivery
- ☐ Tiered support model implemented so common issues don't require senior IT architect intervention
Asynchronous support across time zones. You can't have IT available 24/7 for every global employee. Your system needs to work when IT is asleep.
Automated status updates: "We've received your enrollment issue and will respond within 4 hours." Clear escalation criteria: what's urgent (can't work at all) versus what can wait (missing one non-critical app). Documentation that empowers people to solve common problems independently instead of waiting for IT to wake up.
Buffer time in everything. If you promise a device will be ready on someone's start date, ship it 3 days early. If enrollment takes 2 hours in perfect conditions, tell people to allow 4 hours. Build slack into your timelines.
When things go wrong, and they will, you're not immediately behind schedule. You have room to fix issues without creating a crisis.
Monitor for silent failures. This is the sneaky one. Some enrollment issues don't generate errors. The device enrolls "successfully" but with incomplete configuration. An app didn't install. A security policy didn't apply. A certificate didn't provision.
Everything looks fine in your MDM dashboard. The user doesn't know what's supposed to be there, so they don't report it. Three months later you discover 30% of your fleet is missing critical security configurations.
You need active monitoring that validates not just enrollment completion, but configuration completeness. Run checks 24 hours after enrollment: Are all expected apps present? Are all policies applied? Are all certificates valid?
Tiered support so exceptions don't bottleneck. If every exception requires your senior IT architect to intervene, you've created a single point of failure. That person becomes a bottleneck. They burn out. They leave. Your entire ZTD process collapses.
Build tiers. Common issues get handled by junior staff or automated responses. Medium complexity goes to mid-level techs. Only genuinely weird edge cases escalate to senior resources.
Most companies do the opposite. Everything escalates to the most knowledgeable person because "they can fix it fastest." Short-term true, long-term disaster.
The companies that actually succeed with ZTD spend more time designing failure modes than success paths. They run pre-mortems: "What could go wrong?" Then they build systems to handle those scenarios proactively instead of reactively.
You can't eliminate exceptions. But you can make them less disruptive by planning for them as part of your core design, not treating them as edge cases that shouldn't happen.
Because they will happen. Constantly. That's not a bug in your system, that's reality asserting itself against your beautiful automation.
When you're thinking about what is zero touch provisioning in practice, remember that the best implementations account for when automation fails, not just when it succeeds.
Implementing effective device deployment strategies means building exception handling into your core workflow from day one.
Security Posture vs. Employee Experience (Or: How to Make Everyone Hate You)
Your security team wants total device control. Your employees want to actually get work done.
These goals aren't incompatible. But most companies implement security like they're actively trying to make them incompatible.
You enforce FileVault encryption on every Mac. Smart. But you don't explain why it matters or what happens if someone loses their device. To employees, encryption is just another confusing step during setup that slows everything down.
You restrict admin rights to prevent malware. Reasonable. But your designers need font management tools, your developers need Docker, your video team needs codec packs. Now you're drowning in exception requests, which defeats the entire purpose of restricting admin rights.
And my personal favorite: aggressive MDM controls that feel like surveillance.
You can remotely view device location, installed apps, usage patterns. Employees know this. They feel monitored. Trust erodes. Some start using personal devices for work to avoid oversight, which creates way bigger security risks than whatever you were trying to prevent.
Congratulations, your security policy pushed people into less secure behavior.
Where this typically goes wrong:
MFA that's technically correct but practically annoying. MFA is essential. I'm not arguing against MFA. But requiring it every 4 hours regardless of context? Forcing password changes every 30 days (which research shows encourages weaker passwords, by the way)? That's security theater, not security improvement.
Blocking tools people actually need. Your approved app catalog doesn't include the project management tool an entire department uses because it hasn't gone through security review yet. The review process takes 4-6 weeks. There's a backlog of 30 applications waiting.
The department can't wait 6 weeks. They need to work. So they create personal accounts and start sharing company files through those accounts.
Real example: Product design team needs Figma to collaborate with external contractors. Security hasn't approved Figma. Designers create personal Figma accounts, share company design files through personal email addresses. Now sensitive product designs exist outside company control, no audit trail, no DLP, no way to revoke access when a contractor relationship ends.
The security policy designed to protect company data pushed it into a less secure environment. Well done.
Update enforcement at the worst possible times. Mandatory OS updates that trigger during work hours and require 45 minutes of downtime. Yes, patches are critical. No, forcing them during a client presentation isn't the right approach.
I watched someone's laptop force-restart for updates in the middle of a demo to a prospect. They lost the deal. Great security, though.

Overly restrictive network policies. Your VPN blocks access to legitimate services because they share infrastructure with risky domains. Employees can't access tools they need for work. So they disable the VPN.
Now you have zero visibility into what they're doing and zero protection for their traffic. Your restrictive policy caused the exact behavior it was meant to prevent.
The problem isn't the security requirements. It's implementation that ignores how humans actually work.
Better approaches that don't require weakening security:
Contextual security based on actual risk. Apply stricter controls to high-risk roles, finance, legal, executives with access to sensitive data. Lighter controls for lower-risk roles. Not everyone needs the same security posture.
Your sales team doesn't need the same restrictions as your CFO. Treating them the same is lazy policy design.
Transparent communication about why policies exist. "We require encryption because if your laptop is stolen, customer data could be compromised. This protects both the company and you from legal liability."
Understanding breeds compliance. Mystery breeds resentment and workarounds.
Just-in-time admin access. Instead of permanently restricting or granting admin rights, use tools that let people request temporary elevated access for specific tasks. They install what they need, permissions automatically revert after 30 minutes.
Security without constant exception requests. Tools like Privileges for Mac or SAP for Windows make this straightforward.
| Security Friction Point | Traditional Approach | Balanced Approach |
|---|---|---|
| Admin rights management | Blanket restriction for all users; manual exception requests that take days to approve | Just-in-time elevation tools (Privileges, SAP, Kandji Self Service) that grant temporary admin access for specific tasks, then auto-revoke |
| MFA enforcement | Require authentication every 4 hours regardless of context or risk level | Risk-based authentication that requires MFA for new devices/locations but remembers trusted environments for 30 days |
| App installation controls | Maintain approved catalog; 4-6 week security review for new tools; block everything else | Pre-approve common categories (communication, productivity, development); fast-track review process (72 hours) for department-specific tools; provide self-service request portal |
| OS update timing | Force updates immediately when available, regardless of user activity | Defer non-critical updates by 7 days; allow users to schedule within 48-hour windows; only force critical security patches with 24-hour notice |
| Device monitoring scope | Track location, app usage, browsing history, screen time, and all network activity | Monitor only security-relevant data (encryption status, OS version, required app presence, malware signatures); exclude personal usage patterns |
Risk-based authentication. Require MFA when someone logs in from a new location or device. Not every single time they check email from their usual home network.
Adaptive authentication provides security where it matters without creating constant friction.
Fast-track approval for common tools. Maintain a pre-approved list of standard tools. But create a streamlined review process for new requests. If a team needs Notion or Miro, your security review shouldn't take 6 weeks.
Build a framework for evaluating tools quickly. Categorize by risk level. Low-risk tools get approved in 72 hours. Medium-risk gets a week. Only high-risk tools (access to production data, deep system integration) require lengthy review.
None of these suggestions weaken security. They apply it intelligently instead of bluntly.
The companies that get this right involve end users in security policy design. They ask "what would make this less annoying while still protecting company data?" and actually incorporate that feedback.
Security that employees actively resist is bad security, regardless of how technically sound it is on paper. You need buy-in. Buy-in comes from respecting that people have jobs to do and your policies should enable that work, not obstruct it. If your security posture requires employees to develop workarounds to get their jobs done, you've failed. You've just created shadow IT and lost visibility into what's actually happening.
The Procurement Blindspot That Kills Your Entire Automation
Your MDM is perfectly configured. Policies tested. Enrollment profiles ready. Everything's automated and beautiful.
Then procurement takes 6 weeks to order a laptop because the vendor requires three quotes and two approval signatures.
All your automation sits there, useless, while bureaucracy does its thing.
Procurement is where most ZTD initiatives actually stall. Nobody talks about this because it's not sexy. Vendor blogs want to tell you about elegant MDM configurations, not purchase order workflows.
But you can't deploy devices you haven't bought. You can't automate workflows when vendor lead times are "somewhere between 2 and 8 weeks, we'll let you know." You can't maintain zero-touch when your purchasing system requires IT to manually enter serial numbers into spreadsheets that get emailed to finance for approval.
The disconnect between IT and procurement systems. Your MDM needs device serial numbers before hardware ships so it can pre-register them for auto-enrollment. Your procurement system captures serial numbers after purchase orders close, sometimes days or weeks later.
There's no integration between systems. Someone manually transfers data. That manual step introduces errors, typos in serial numbers mean devices won't auto-enroll, and delays. If the person responsible is on vacation, nothing happens.
Vendor coordination failures everywhere. You arranged for Apple to automatically register devices in your ADE portal when they ship. Perfect.
But you're also buying refurbished devices from a third-party vendor who doesn't have access to your ADE account. Those devices can't auto-enroll. Now you have two classes of hardware with different provisioning workflows, and your automation only covers one.
Or, this happened last month to a client, the vendor registered devices in the wrong ADE portal. They have multiple clients, mixed up the accounts. All 50 devices tried to enroll in someone else's MDM. Took three days to untangle.

Supply chain chaos. You hire someone. You order their laptop. Vendor says 2-week delivery. Three weeks later, still hasn't shipped. Component shortages, they say. The employee starts in 4 days.
You scramble for alternative hardware. Find something, but it's not the same model you tested your configurations on. Your automation assumes device consistency. Reality doesn't provide it. Now you're troubleshooting why certain policies don't apply correctly to this specific model while your new hire waits.
Bulk purchasing versus actual needs. Procurement negotiated a great deal on a specific laptop model. Bought 100 units. Unfortunately, your design team needs better GPUs, and your developers need different specs.
The bulk purchase doesn't match requirements. You end up with unused inventory gathering dust and emergency purchases of correct devices at higher costs, bypassing your automated procurement workflow entirely.
International purchasing is a nightmare. Ordering devices for US employees is straightforward. Ordering for employees in Brazil, India, or Germany involves different vendors, different lead times, import regulations, local tax requirements, customs delays.
Your automation works domestically but completely falls apart internationally. You're back to manual coordination for 30% of your workforce. We map these cross-border buying challenges in the state of global IT hardware procurement.
And good luck getting consistent hardware models globally. The MacBook Pro configuration available in the US might not be the same SKU available in India. Your carefully tested MDM policies might behave differently on slightly different hardware specs.
Asset tracking gaps. Device ships to employee. It arrives. But your asset management system doesn't update because the shipping confirmation didn't trigger the right webhook. You don't know it was delivered.
Employee starts using it. Six months later you're trying to reconcile inventory and can't account for that device. Your automation deployed it but lost track of it.
Or worse: device ships, gets stolen off a porch, employee reports it never arrived, but your system shows "delivered" so finance won't approve a replacement without an investigation. Employee sits without equipment for a week while you sort it out.
Procurement Integration Requirements Template
Use this framework when evaluating hardware vendors or procurement platforms for ZTD compatibility:
Vendor Technical Requirements:
- Must support automated MDM registration (ADE for Apple, Autopilot for Windows) before shipment
- API access for real-time order status, tracking, and serial number data
- Webhook support to trigger asset management system updates on shipment/delivery
- Ability to provide device serial numbers within 24 hours of purchase order confirmation
Process Requirements:
- Maximum lead time commitment with penalty clauses for delays beyond X days
- Defined escalation process for urgent orders (new hire starts in <5 days)
- Support for international shipping to [list your key countries] with customs pre-clearance
- Flexible return/replacement process for defective devices (cross-ship within 48 hours)
Data Integration Requirements:
- Serial number export in standardized format (CSV, JSON via API)
- Automatic sync with asset management platform [specify yours: ServiceNow, Jamf Pro, Kandji, etc.]
- Order status visibility without manual portal login (API or automated email parsing)
Contract Terms:
- SLA for ADE/Autopilot registration: 100% of devices registered before shipment
- Penalty clause for registration failures that cause deployment delays
- Quarterly business review to assess performance against delivery timelines and quality metrics
How to actually fix procurement blindspots:
Integration between procurement and IT systems. Your purchasing platform should automatically feed device information to your MDM. Serial numbers, models, purchase dates, assigned users should flow between systems without manual data entry.
This requires either buying platforms that integrate natively or building custom connections. Most companies don't want to invest in this because it's not exciting. But it's the difference between automation that works and automation that requires constant manual intervention.
Vendor requirements in contracts. When you negotiate with hardware vendors, include clauses requiring ADE/Autopilot registration before shipment. Make it a procurement requirement with penalties for non-compliance, not an IT afterthought.
We've seen companies add "100% of devices must be registered in customer's MDM portal before shipment, with penalty clauses for registration failures" to their vendor contracts. Suddenly vendors take it seriously.
Buffer inventory for emergencies. Maintain a small stock of pre-configured devices for emergency situations. New hire starts Monday, their ordered device is delayed, you need a backup option.
Yes, this costs money. Devices sitting in inventory aren't free. But you know what else costs money? Employees sitting idle for a week waiting for equipment. Or losing a candidate because you can't get them a laptop in time.
We usually recommend keeping 5% of your quarterly deployment volume as buffer stock. If you're deploying 100 devices per quarter, keep 5 ready to go.
Standardize hardware across the organization. Reduce the number of device models you support. Fewer models means simpler configurations, easier troubleshooting, better bulk purchasing leverage.
Exceptions should require justification, not be the default. "I want a different laptop" isn't a reason. "I need a different GPU for video rendering" is a reason.
Most companies let people choose whatever they want, then wonder why they're supporting 15 different device configurations with incompatible policies.
Multi-vendor strategies for supply chain resilience. Don't depend on a single vendor. If Apple has 8-week lead times, you need relationships with other suppliers who can provide alternatives.
Yeah, this complicates your automation because you're supporting multiple device types. But it's better than telling new hires "sorry, you can't start for two months because our vendor is backordered."
You can build the most sophisticated ZTD automation in the world, but if procurement can't reliably get devices ordered, registered, and shipped on predictable timelines, your automation is irrelevant.
Fixing this requires treating procurement as part of your ZTD strategy, not a separate function that happens before automation kicks in. The handoff between procurement and IT is where most implementations break. Eliminate the handoff by integrating the systems.
When people ask what is zero-touch in practice, the answer often comes down to procurement coordination more than technical capability.
Understanding IT procurement solutions is critical to closing the gap between technical automation readiness and operational procurement reality.
When Zero Touch Becomes Zero Visibility (And You're Flying Blind)
You removed IT from the deployment process. Congratulations, you also removed their eyes.
When IT manually provisioned devices, they saw problems immediately. Device wouldn't power on? They knew. App wouldn't install? They saw it fail. Configuration caused a kernel panic? They were right there when it happened.
With ZTD, devices ship directly to employees. Problems surface only when users report them. If they report them.
Some employees struggle through issues without creating tickets. They assume the problem is their fault or something they need to live with. Your metrics show "successful enrollment," but the actual user experience is broken and you have no idea.
Silent configuration failures are everywhere. Device enrolls in your MDM. Status shows "Success." But three of the twelve apps that should have installed didn't.
The user doesn't know those apps should be there. They only discover the gap weeks later when they need a tool that's missing. Your monitoring didn't catch it because it only checked enrollment status, not configuration completeness.
I've seen companies with 30% of their fleet missing critical apps because their validation only checked "did enrollment complete?" not "did everything that was supposed to happen actually happen?"
Performance issues nobody connects to your policies. The security agent you deployed consumes 40% of CPU during scans. Devices slow to a crawl. Users think their hardware is defective.
They don't connect the performance problem to a specific app because they don't know what's running in the background. You don't see the issue unless you're actively monitoring resource usage across the fleet. Most companies aren't.
User workarounds that hide real problems. Employee can't access a shared drive due to permission misconfiguration. Instead of creating a ticket, they ask a coworker to download files and send them via personal email.
The workaround functions well enough that they never report the underlying problem. You have a permissions issue affecting multiple users, but zero visibility into it. The issue persists for months because nobody told you it exists.

Devices that fall out of management. Employee accidentally removes the MDM profile while troubleshooting something else. Device continues functioning for most tasks. Your MDM shows "last check-in 47 days ago" but doesn't actively alert you.
The device is now unmanaged, potentially non-compliant, and you don't know until you try to push a critical security update six months later and it fails. How many other devices are in this state? You have no idea.
Geographic patterns you can't see in aggregate metrics. Your automation works fine for employees in major cities with fast internet. It fails frequently for remote workers in areas with limited connectivity.
You don't see the pattern because you're looking at aggregate success rates. "87% successful enrollment!" Great. Where's the 13% failure concentrated? Which regions? Which ISPs? Which device models? You don't know because you're not segmenting the data.
Building visibility back into ZTD:
Monitor beyond enrollment status. Track whether all expected configurations applied, all required apps installed, all security policies activated, all system resources performing within acceptable ranges.
Don't just check "did the device enroll?" Check "is the device fully configured and functioning correctly?"
Proactive health checks. Automatically run validation scripts 24 hours after enrollment. Verify everything is working. If a device fails validation, create a ticket automatically before the employee notices a problem.
We've seen this catch issues that would have gone unreported for weeks or months. User doesn't know Slack should auto-install, so they don't report it missing. Your health check catches it within 24 hours.
User feedback loops. Send a survey 3 days after device delivery. "Did everything work as expected? Can you access all the tools you need? Did you encounter any issues?"
Collect data directly from users instead of waiting for them to self-report problems. Most people won't create a ticket for minor annoyances, but they will answer a quick survey.
Anomaly detection. Use monitoring tools that identify outliers. If 95% of devices complete enrollment in under 30 minutes but 5% take over 2 hours, investigate why.
If certain app installations fail more frequently on specific device models or OS versions, that's a pattern worth examining. Aggregate metrics hide these patterns. Segmented analysis reveals them.
Regular compliance audits. Periodically scan your entire fleet to verify devices remain in compliance with security policies. Encryption enabled, firewall active, required apps present, OS version current.
Don't assume that because a device enrolled correctly six months ago, it's still properly configured today. People change settings. Policies drift. Apps get uninstalled. Verify continuously.
Asset lifecycle tracking. Know where every device is at every stage. Ordered, shipped, delivered, enrolled, in use, needs repair, decommissioned.
If you can't account for a device's status at any given moment, you have a visibility problem. And visibility problems become security problems when you can't track where company data is.
The goal isn't to recreate the manual oversight you eliminated. It's to build automated oversight that provides the same or better awareness without requiring manual intervention.
What is zero touch if not a system that removes physical interaction while maintaining operational awareness? Zero-touch should mean IT doesn't need to physically handle devices. It shouldn't mean IT doesn't know what's happening with devices.
A ZTP server and automated systems only work when you can verify they're working. Visibility isn't optional in modern device management.
Implementing comprehensive IT asset management ensures you maintain visibility even as you remove manual touchpoints from your deployment process.
Automation without visibility is just flying blind faster.
How GroWrk Actually Solves This Mess
Okay, you've read 4,000 words about everything that breaks with zero-touch deployment. Procurement delays. Configuration debt. Visibility gaps. Exception handling. The Grand Canyon-sized gap between automation theory and operational reality.
So what do you actually do about it?
Most companies try to solve this by stitching together separate systems. A procurement platform. A logistics provider. An MDM solution. An asset tracking tool. Each system works independently. The gaps between them create all the friction we've been talking about.
GroWrk exists because we got tired of watching companies struggle with these gaps.
We built a single platform that handles device procurement, global shipping, automated configuration, deployment, ongoing management, repairs, and retrieval. You're not coordinating between five vendors. You're working with one system that manages the entire device lifecycle.

What this actually solves:
Procurement integration that works. When you order a device through GroWrk, we automatically handle MDM registration before shipment. Serial numbers flow into your management system without manual data entry. The procurement blindspot disappears because procurement and IT functions are integrated from the start.
No spreadsheets. No manual serial number transfers. No devices showing up that can't auto-enroll because someone forgot to register them.
Global logistics without the headache. We manage international shipping, customs, import regulations, local vendor relationships. You order a device for someone in Singapore the same way you order one for someone in Ohio.
The complexity is our problem, not yours. We deal with the fact that Brazilian customs requires different documentation than German customs. You just click "order device." See how Upwork centralized device logistics across 30+ countries with GroWrk.
Pre-configured devices. We apply your MDM profiles, install required apps, configure security settings before devices ship. Employees receive hardware that's ready to use out of the box.
Actual zero-touch, because we handle the touch before delivery. Your IT team doesn't touch devices. We do, so employees don't have to.
Real-time visibility across the lifecycle. You can see exactly where every device is at any stage. Ordered, in transit, delivered, enrolled, in use. Our dashboard provides the observability that typical ZTD implementations lack.
No more "where's the laptop I ordered three weeks ago?" No more "did this device actually get delivered or was it stolen off a porch?" You know.
Exception handling built in. When issues arise, delivery delays, hardware defects, configuration failures, we have support teams and backup inventory to resolve them quickly.
Device arrives with a dead pixel? We cross-ship a replacement within 48 hours. Enrollment fails because of network issues? Our support team helps troubleshoot. You're not coordinating device replacements or walking users through manual enrollment at midnight.
Flexible policies without configuration debt. Our platform lets you define role-based configurations without building complex policy matrices. You specify what different teams need, we ensure devices are configured correctly for each user.
You don't maintain hundreds of overlapping policies. We handle the complexity of translating "Marketing needs these apps, Engineering needs those apps, Finance needs these security settings" into actual device configurations.
Look, I'm obviously biased here, this is our platform. But we built it specifically because we kept seeing companies struggle with the same problems. The gap between ZTD theory and reality. The procurement nightmares. The visibility blackouts. The exception handling that requires constant manual intervention. If you're experiencing these problems, we should talk. We've built our entire business around solving them.
Final Thoughts (If You're Still Here)
Zero-touch deployment works. The technology is real. The automation is solid.
What doesn't work is treating ZTD as a complete solution instead of one component of device management.
You can automate enrollment perfectly and still fail at deployment if procurement takes 6 weeks. You can have flawless MDM configurations and still create terrible experiences if your security policies ignore how humans actually work. You can eliminate manual provisioning and still need a large IT team because the labor shifted to policy management and exception handling.
The companies succeeding with ZTD recognized these gaps early and built systems to address them. They integrated procurement with IT instead of treating them as separate functions. They designed for exceptions, not just happy paths. They maintained visibility even after removing manual touchpoints. They balanced security with usability instead of treating them as opposing forces.
Most importantly, they understood that zero-touch doesn't mean zero effort. It means redirecting effort from repetitive manual tasks to strategic system design, proactive monitoring, and continuous improvement.
The hidden overhead we've explored, invisible labor, configuration debt, procurement blindspots, visibility gaps, represents the real cost of ZTD. Vendor marketing focuses on what you eliminate. We've focused on what you transform and what you need to build to make that transformation successful.
If your ZTD implementation still feels demanding, you're not failing. You're experiencing the normal gap between automation theory and operational reality.
The question is whether you're building systems to close that gap or just accepting it as the cost of doing business.
The difference between companies where ZTD delivers on its promise and companies where it creates new problems is straightforward: the successful ones solved for the entire device lifecycle, not just the enrollment moment. That whole-lifecycle view is what we explore in the state of IT lifecycle management.
Enrollment is one event. Device management is ongoing. Optimizing for the event while ignoring the lifecycle is how you end up with automation that technically works but operationally fails.
If you've made it this far, you either have a real ZTD problem or you're procrastinating something worse. Either way, you now know what actually breaks and what you need to fix.
Good luck. You're going to need it.
What is zero touch deployment when it works as promised?
The practical answer to what is zero touch deployment is a model where a device ships straight to the user and configures itself on first boot, with no manual imaging. Done right, zero touch deployment moves effort upstream into planning and policy rather than removing it. Teams that treat zero touch deployment as an ongoing discipline, not a one-time setup, are the ones that actually see the productivity gains, because zero touch deployment only pays off when the exceptions are designed for in advance.


