

Three in the morning, and I'm staring at my phone trying to make sense of what our CTO is saying. He's talking fast, too fast, something about ransomware and locked databases and "we're completely screwed."
I remember thinking he was overreacting. He wasn't.
By 6 AM, we knew the damage: $2.3 million. Our entire customer database locked down. And our backup strategy? That's generous. We had backups. They were just... also encrypted. Because apparently, we'd been backing up to network drives that the ransomware could reach. Looking back, we were idiots. Expensive idiots.
The board meeting that afternoon was brutal. I had to explain how a company our size, with our revenue, had basically no disaster recovery plan worth mentioning. We survived, barely. A lot of companies don't.
And here's the thing: we weren't unique. Gartner's 2025 research shows 63% of organizations have now implemented strategic IT frameworks specifically to prevent the kind of catastrophic failure we experienced. The question isn't whether you need an IT strategy anymore. It's which one you choose, and whether you implement it before or after your own 3 AM wake-up call.
This guide covers the 19 IT strategy examples that actually work. Not theory. Not consultant-speak. Real frameworks that real companies use to avoid becoming cautionary tales.
Table of Contents
- Building From the Ground Up
- Zero-Trust Architecture Rollout
- Cloud-First Migration Plan
- API-Led Integration Framework
- Infrastructure as Code Adoption
- Multi-Cloud Redundancy Model
- Protecting What Matters
- Endpoint Security Hardening
- Data Classification and Governance
- Incident Response Playbook Development
- Identity and Access Management Overhaul
- Security Awareness Training Program
- Enabling People, Not Just Systems
- Remote Work Technology Enablement
- Self-Service IT Portal Implementation
- Device Lifecycle Management
- Bring Your Own Device (BYOD) Policy
- Digital Employee Experience Monitoring
- Making Smarter Decisions
- IT Asset Inventory and Optimization
- Technology Spend Analysis
- Vendor Consolidation Initiative
- Service Level Agreement (SLA) Redesign
- Final Thoughts
TL;DR
- Most IT strategies are PowerPoint theater. These 19 actually fix problems.
- Get your foundation right (zero-trust, cloud-first, APIs) or everything else is built on sand.
- Security isn't about compliance. It's about not getting wrecked when (not if) you get breached.
- Your employees are drowning in IT friction. Self-service portals and proper device management fix this.
- You're probably wasting 30% of your IT budget and don't know where. Asset inventory and spend analysis show you.
- The difference between companies with IT strategies and companies with IT results is simple: one group does the work.
Building From the Ground Up
Here's what nobody tells you about infrastructure decisions: you're going to live with them for the next five years minimum. Maybe ten if you're unlucky. That cloud architecture you're about to commit to? That integration approach? Those choices will either give you room to grow or trap you in technical debt that gets worse every quarter.
I'm starting with infrastructure because everything else depends on it. Get this wrong and nothing else matters. Get it reasonably right and you've got options.
The strategies here focus on architecture, integration, and deployment models that give you room to grow without ripping everything out in 18 months. Because changing foundational decisions later costs exponentially more than getting them reasonably right upfront. The same long-term thinking applies to the hardware your teams rely on, which we cover in the state of IT lifecycle management.
| Infrastructure Strategy | Primary Benefit | Implementation Complexity | Time to Value |
|---|---|---|---|
| Zero-Trust Architecture | Continuous security verification | High (but worth it) | 12-18 months* |
| Cloud-First Migration | Scalability and reduced capital expense | Medium to High | 6-24 months (depends on your mess) |
| API-Led Integration | Reusable, maintainable connections | Medium | 6-12 months |
| Infrastructure as Code | Consistent, auditable environments | Medium | 3-9 months |
| Multi-Cloud Redundancy | Resilience against vendor outages | High (maybe too high) | 12-24 months |
- Add 6-12 months if you hit political roadblocks, which you will.

1. Zero-Trust Architecture Rollout
Remember when we all thought firewalls were enough? Cute times.
Zero-trust throws that whole idea out. Nothing is trusted by default. Not users. Not devices. Not applications. Everything gets verified. Every time. Yes, even Karen from accounting trying to access the same spreadsheet she's opened daily for three years.
Sounds paranoid? It is. It's also the only security model that makes sense when your "network perimeter" is every employee's home WiFi and coffee shop they work from.
The rollout requires mapping all data flows (yes, every one), defining access policies based on context, and deploying tools that enforce these policies without grinding productivity to a halt. Start with your most sensitive systems and expand outward. Learn as you go rather than attempting a big-bang transformation that'll fail spectacularly.
When implementing zero-trust principles, organizations should consider how identity and access management for remote teams creates additional verification layers that strengthen security posture without compromising user experience.
Here's where everyone screws up: they underestimate the cultural shift required. Zero-trust sounds great until your VP of Sales can't access Salesforce from his home network and calls the CEO at 6 AM screaming. You'll face this exact scenario. Have a plan for executive exceptions or your project is dead.
Your team needs to embrace the mindset that trust is never implicit. Every access request gets verified. Every. Single. Time.
2. Cloud-First Migration Plan
Cloud-first means your default answer is "yes" to cloud. You need a damn good reason to say no, not just "Bob doesn't trust it" or "we've always done it this way." I mean actual reasons: compliance requirements that mandate on-prem, physics problems (latency), or real cost analysis that proves on-prem is cheaper.
Here's what your plan actually needs:
- Decision criteria that aren't just "because cloud is cool"
- A prioritized list of what moves first (hint: not everything at once)
- Governance that stops people from spinning up $50K/month experiments on their corporate card
The most effective plans include a detailed assessment of current applications, dependencies mapped, and a realistic timeline that accounts for data transfer limits and team learning curves.
I've watched companies treat migration like moving furniture to a new house. Just pick it up and put it somewhere else, right? Wrong. You're not just moving servers to someone else's data center. You're changing how you consume and scale infrastructure. Lift-and-shift is how you spend cloud money for on-prem performance.
The financial model matters more than most teams realize. Cloud costs are variable, which means they can spiral if you don't implement proper governance and monitoring from day one. Budget 1.5-2x what you initially estimate. I'm serious. Every cloud migration I've seen costs more than planned.

3. API-Led Integration Framework
I worked with a retail company in 2021 that had 14 different e-commerce platforms running simultaneously because of acquisitions. Their integration architecture was literally a spreadsheet with 200 rows of point-to-point connections. When one system went down, nobody knew what else would break. It took us 18 months to untangle.
Point-to-point integrations create spaghetti architectures that become unmaintainable. An API-led strategy establishes reusable integration layers (system APIs, process APIs, experience APIs) that decouple your applications from each other.
Build a catalog of standardized interfaces that any system can consume without custom coding for each connection. Define API design standards, security protocols, versioning policies, and a developer portal for internal teams.
You're investing upfront in infrastructure that pays dividends every time you add a new tool, retire a legacy system, or need to expose data to partners. The alternative? Maintaining dozens of brittle, undocumented connections that break whenever anything changes.
This enables cloud-first migration to actually work. Without API-led integration, cloud migration becomes point-to-point spaghetti in someone else's datacenter.
4. Infrastructure as Code Adoption
Manual server configuration doesn't scale. More importantly, it creates environments that drift from documented standards, and suddenly nobody knows what's actually running in production.
Infrastructure as Code treats your infrastructure definitions as software. Version-controlled. Deployed through automated pipelines. Peer-reviewed like any other code.
Select tools (Terraform, CloudFormation, Ansible), establish coding standards, and train teams on the mindset shift from clicking through consoles to writing declarative configurations.
The real value emerges when you can spin up identical environments for development, testing, and production in minutes, with full audit trails of every change. Organizations pursuing infrastructure modernization benefit from understanding IT infrastructure automation best practices that reduce manual configuration errors and accelerate deployment cycles across distributed environments.
The biggest barrier isn't technical. It's getting operations teams comfortable treating infrastructure like code, complete with peer reviews and testing pipelines. I used to think this was overkill for small companies. I was wrong. Even at 50 people, the time savings justify the upfront investment.

5. Multi-Cloud Redundancy Model
Unpopular opinion: Multi-cloud is overrated for 90% of companies.
Vendor lock-in isn't just about pricing leverage. It's about resilience when a single cloud provider has an outage that takes down half the internet. A multi-cloud strategy distributes critical workloads across providers, ensuring no single point of failure.
This requires abstracting your applications from provider-specific services (way harder than it sounds), implementing cross-cloud networking, and establishing operational procedures for managing multiple consoles and billing systems.
Here's the thing: multi-cloud complexity isn't free. You're adding operational overhead, increasing the skills required from your team, and potentially sacrificing some cloud-native features for portability.
Identify which workloads genuinely need this level of redundancy versus which can tolerate downtime. True multi-cloud architecture makes sense for mission-critical systems but creates unnecessary complexity for everything else. Unless you're Netflix or Spotify, the complexity probably isn't worth it. Pick one cloud provider and get really good at it.
But I'll admit the real value of multi-cloud isn't redundancy. It's negotiating leverage. When AWS knows you can move workloads to Azure, pricing conversations get interesting.
Protecting What Matters
Security strategies get reduced to compliance checkboxes or tool purchases. The examples here focus on practical protection that accounts for human behavior, evolving threats, and the reality that breaches are a question of when, not if.
These strategies assume compromise and build resilience accordingly. Prevention is overrated. You will get breached. Spend more energy on detection and response.
Technology alone can't solve security problems. You need processes, training, and a culture that treats security as everyone's responsibility.
6. Endpoint Security Hardening
Here's a fun fact: 80% of breaches start at endpoints. Your laptops are the front door, and most of them are wide open.
Hardening strategies involve deploying endpoint detection and response (EDR) tools, enforcing disk encryption, disabling unnecessary services, and implementing application whitelisting. You're reducing the attack surface by removing or locking down anything that isn't essential for business function.
Establish baseline configurations for different device types, automated compliance checking, and remediation workflows when devices drift from standards.
Look, security that makes devices unusable is worthless. I don't care how locked down it is. If your employees can't work, they'll find workarounds that are even less secure. Your hardening approach needs to be aggressive enough to protect against real threats but pragmatic enough that employees don't revolt.
With devices scattered across 40 countries, endpoint hardening isn't optional anymore. It's your only consistent security layer.

7. Data Classification and Governance
You can't protect data you can't identify or locate. Classification strategies involve tagging data based on sensitivity (public, internal, confidential, restricted), implementing controls tied to each classification level, and establishing governance processes for data lifecycle management.
Deploy tools that automatically discover and classify data across repositories. Define retention policies. Train employees to classify information they create. Phase implementation by data type, starting with regulated information like PII, PHI, and financial records before expanding to broader intellectual property.
Data protection strategies must align with IT compliance standards and frameworks that govern how organizations handle sensitive information across jurisdictions and regulatory environments.
Most teams underestimate the sheer volume of unstructured data scattered across file shares, email systems, and collaboration platforms. Discovery alone can take months. Classification and remediation take longer.
If you're in healthcare, this isn't optional. HIPAA will destroy you if you get this wrong. Financial services? Your regulators are already breathing down your neck about this. Start here.
8. Incident Response Playbook Development
Chaos during a security incident costs you time, data, and credibility. A response playbook documents exactly who does what when you detect a breach, from initial triage through containment, eradication, and recovery.
Identify response team members. Define escalation paths. Establish communication protocols for internal and external stakeholders. Conduct tabletop exercises to test the playbook. The most effective playbooks include decision trees for common scenarios, pre-approved messaging templates, and integration with your legal and PR teams.
This isn't a document you write and file away. It's a living framework you update after every incident and drill.
The worst BYOD implementation I've seen: IT could remotely wipe any device enrolled in MDM. An employee quit, they wiped his phone, and deleted his kid's baby photos. He sued. The company settled. Your incident response needs to account for scenarios like this.
I've seen the difference between organizations with tested playbooks and those winging it during an incident. The prepared ones contain the breach faster, communicate more effectively, and recover with less damage to reputation and operations.
When incident response stalls: You'll hit a scenario your playbook doesn't cover. Don't freeze. Make a decision, document it, and update the playbook afterward. Imperfect action beats perfect paralysis.
9. Identity and Access Management Overhaul
Passwords are a terrible authentication method, but they persist because alternatives require infrastructure and change management. An IAM strategy implements single sign-on ( SSO), multi-factor authentication (MFA), and automated provisioning/deprovisioning tied to HR systems.
Centralize identity management so users authenticate once and access everything they need (and nothing they don't). Migrate applications to support modern authentication protocols. Establish role-based access controls. Implement periodic access reviews to catch permission creep.
That 15-year-old Oracle database running your entire order management system? Yeah, it doesn't speak OAuth. We had a client still running a DOS-based inventory system (yes, DOS) and trying to integrate it with Azure AD was... an adventure.
You'll find dozens of legacy systems that authenticate with hardcoded passwords in config files. Budget 3x what you think for remediation. That "12-18 months" timeline? Add 6 months if you have political roadblocks, which you will.
When your team logs in from coffee shops in 15 time zones, MFA isn't paranoia. It's basic hygiene.
10. Security Awareness Training Program
Controversial take: Security awareness training doesn't work. People will always click phishing emails.
But you know what? Untrained people click MORE phishing emails. It's harm reduction, not elimination.
Move beyond annual compliance videos to continuous, engaging education that changes behavior. Run simulated phishing campaigns with immediate feedback. Deploy microlearning modules delivered in the workflow. Use gamification to drive participation.
Measure not just completion rates but actual behavior change. Click rates on simulated phishes. Reported suspicious emails. Password hygiene improvements.
Tailor content to different roles since developers face different threats than finance teams. Generic training wastes everyone's time and doesn't move the needle on security posture.
The most effective programs combine regular testing with positive reinforcement. Shame doesn't work. Recognition for catching and reporting threats does.
When spend analysis reveals that a company is paying for security training nobody uses, I want to scream. Make it engaging or don't bother.
Enabling People, Not Just Systems
IT exists to make your organization more effective, yet many strategies optimize for technical elegance while making life harder for actual users. The strategies here prioritize employee experience and productivity.
The best technical solution is worthless if adoption fails or if it creates friction that slows people down. Balance control with empowerment, giving employees the tools they need while maintaining security and manageability.
11. Remote Work Technology Enablement
Remote work means solving for connectivity, collaboration, security, and ergonomics, not just throwing up a VPN and calling it done.
Deploy cloud-based productivity suites. Implement virtual desktop infrastructure (VDI) for secure access to sensitive systems. Establish collaboration platforms with clear usage guidelines. Provide home office equipment.
Address connectivity (stipends for internet upgrades, backup options), ergonomics (monitors, chairs, peripherals), and support (extended help desk hours, remote troubleshooting tools). Don't assume everyone has adequate home internet or workspace. They don't.
Organizations building comprehensive remote work strategies should reference a detailed remote onboarding checklist that ensures new hires receive proper equipment, access, and support from day one.
Remote work amplifies existing IT problems. That flaky VPN that was annoying when 10% of staff worked remotely becomes business-critical when 90% depend on it daily. That "12-18 months" timeline for VDI deployment? If you don't have executive support and dedicated resources, double it.
BYOD exploded during COVID when companies had no choice. Now we're figuring out how to do it right instead of just doing it desperately.

12. Self-Service IT Portal Implementation
Your IT team is drowning in password reset tickets. I know this because every IT team is drowning in password reset tickets.
Self-service portals fix this, but only if you build them right. Most companies don't.
Start by looking at your ticket queue. What shows up 50+ times a month? Password resets, software installations, access requests. That's your starting point. Automate those first.
Then build a knowledge base that doesn't suck. Searchable. Actual screenshots. Written by someone who remembers what it's like to not know things. Not "Please refer to documentation in Section 4.2.1" garbage.
Catalog the most frequent support requests. Build automated workflows for fulfillment. Create searchable solutions. Integrate with backend systems like Active Directory, asset management, and procurement.
Include request tracking, approval routing for non-standard asks, and feedback mechanisms to continuously improve the experience. Success metrics focus on deflection rates and time-to-resolution, not just portal usage.
The test: Can someone reset their password at 2 AM without calling anyone? Can they request Zoom and have it installed within an hour? If no, keep building.
I've implemented these across 40+ companies. The pattern is clear: employees will use self-service if it's faster than submitting a ticket. If it takes them ten minutes to navigate your portal when a ticket takes five, you've wasted your money. Make it stupid simple or don't bother.
This represents one of the clearest examples where user experience directly determines ROI. A portal that saves users five minutes but takes them ten minutes to navigate fails regardless of technical sophistication.
| Self-Service Capability | Average Time Saved per Request | Implementation Difficulty | User Adoption Rate |
|---|---|---|---|
| Password Reset | 15-20 minutes | Low | Very High (85-95%) |
| Software Installation Requests | 2-4 hours | Medium | High (70-85%) |
| Access Permission Changes | 1-3 hours | Medium | Medium (60-75%) |
| Hardware Requests | 4-8 hours | Medium to High | Medium (55-70%)* |
| Knowledge Base Search | 10-30 minutes | Low | High (75-90%) |
- Hardware request adoption is lower because the form is confusing. Fix that first.
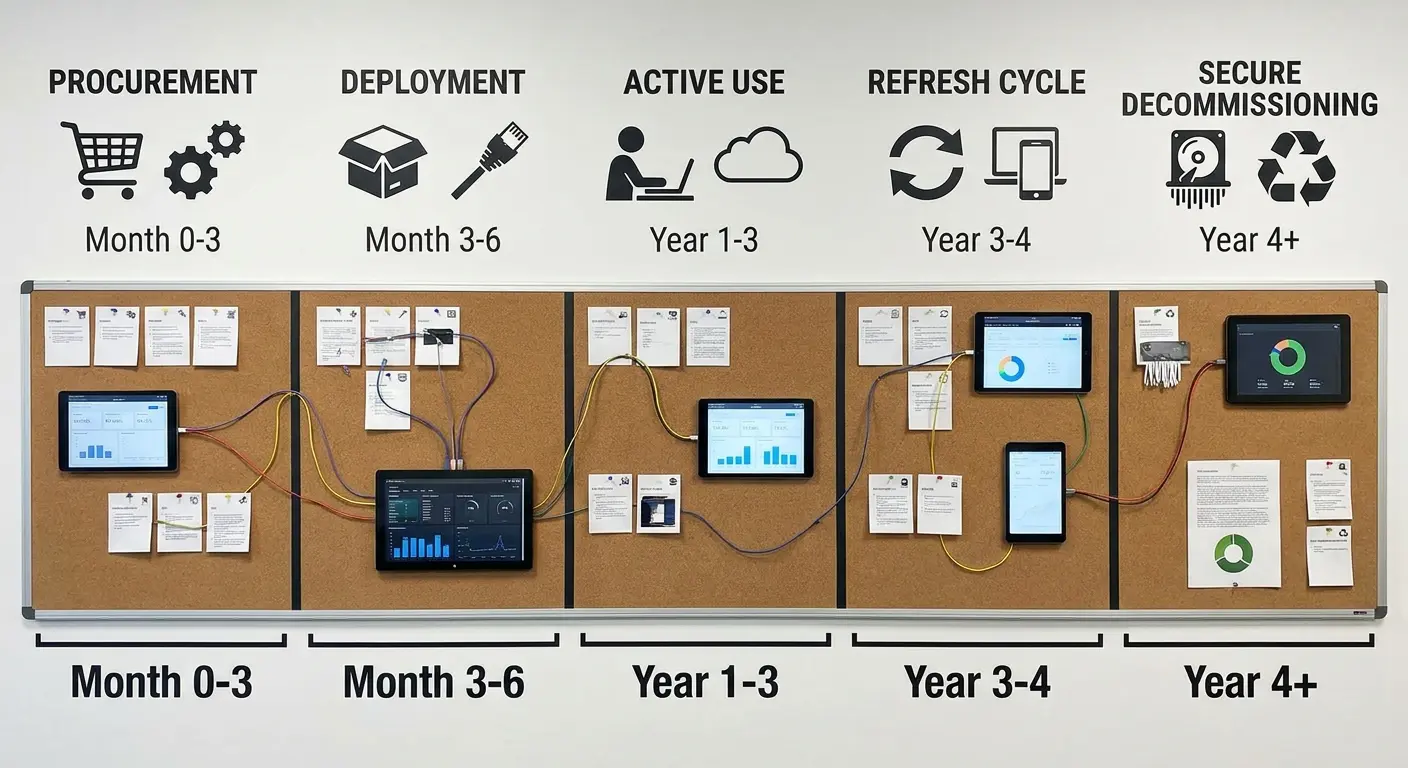
13. Device Lifecycle Management
Device lifecycle management is simple: Buy devices. Deploy them. Replace them every 3 years. Dispose of them securely.
The hard part? Doing this globally.
Devices don't last forever, but many organizations run them until they fail catastrophically. A lifecycle strategy establishes refresh cycles based on device type and usage patterns, implements trade-in or buyback programs to offset costs, and ensures seamless transitions that don't disrupt productivity.
Maintain an asset inventory with purchase dates and warranty expirations. Budget for replacements proactively. Standardize configurations so new devices can be deployed quickly. Include data migration procedures, secure disposal for retired devices, and consideration of refurbished options for non-critical roles.
You're probably dealing with a distributed workforce where tracking devices feels impossible and refresh cycles have stretched from three years to "whenever it breaks."
Full disclosure: This is exactly why we built GroWrk. I got tired of watching companies struggle with device management across 40 countries, so we built a platform that handles the entire lifecycle. Procurement, config, shipping, retrieval, all of it. The lifecycle management happens automatically, from deployment through secure decommissioning. Shameless plug, but it actually solves this problem.
Organizations seeking to optimize hardware refresh cycles should explore comprehensive device lifecycle management practices that balance cost efficiency with employee productivity and security requirements.
The financial impact of poor lifecycle management compounds over time. Aging hardware increases support costs, reduces employee productivity, and creates security vulnerabilities as devices fall out of vendor support windows.
When lifecycle management works: An employee in Singapore needs a laptop. It arrives in 48 hours, pre-configured, ready to go. They're productive immediately. The old laptop gets retrieved, wiped, and redeployed to someone else. You never think about it.
14. Bring Your Own Device (BYOD) Policy
BYOD is a terrible idea that we pretend is good because employees demand it.
Actually, scratch that. The real problem isn't the technology. It's the politics.
Employees want to use their personal devices for work, and prohibiting it just drives behavior underground. A BYOD strategy defines what's allowed (which device types, operating systems, security requirements), implements mobile device management (MDM) to enforce policies without invading privacy, and establishes support boundaries (what IT will and won't troubleshoot).
Address data segregation (work apps and data isolated from personal), acceptable use, and off-boarding procedures when employees leave. Balance employee preference with risk management through containerization that keeps corporate data separate and wipeable.
When developing BYOD policies, organizations must establish clear employee equipment agreements that define ownership, responsibilities, and data protection requirements for personal devices accessing corporate resources.
Privacy concerns kill BYOD programs faster than technical challenges. Employees revolt when they discover IT can wipe their entire phone, including personal photos and apps, if they leave the company. Containerization solves this by isolating corporate data, but you need to communicate how it works and what IT can and cannot access.
Make it opt-in, not mandatory. Have your legal team draft clear consent language before enrollment. The worst implementation I've seen ended in a lawsuit over deleted baby photos. Don't be that company.
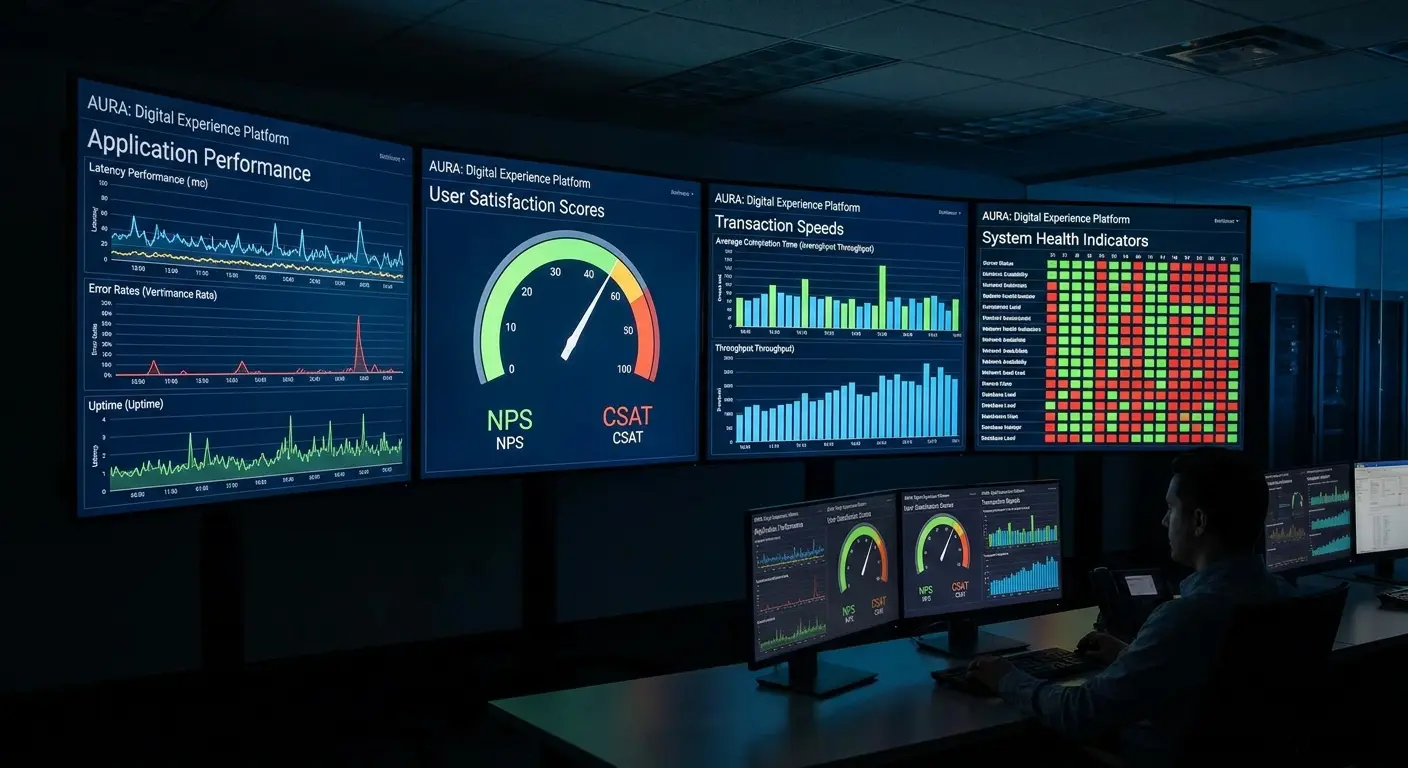
15. Digital Employee Experience Monitoring
You can't improve what you don't measure, and traditional monitoring focuses on infrastructure uptime rather than user experience. Digital experience monitoring (DEM) strategies implement tools that measure application performance from the end-user perspective, tracking metrics like login times, transaction completion rates, and error frequencies.
Deploy agents on endpoints. Implement synthetic monitoring to proactively test critical workflows. Establish baselines to detect degradation.
Include dashboards that correlate experience metrics with infrastructure data, alerting when user experience degrades even if systems appear healthy, and regular reviews to identify improvement opportunities.
Infrastructure teams celebrate 99.9% uptime while users struggle with applications that are technically available but practically unusable due to performance issues. DEM bridges this gap by measuring what users actually experience rather than what servers report.
Honestly, I'm not sure DEM is worth it for most companies yet. The tools are expensive and the insights often just confirm what you already know. But it's evolving fast. If you're a large enterprise with complex application stacks, it might be worth the investment.
Making Smarter Decisions
IT budgets are under constant scrutiny, yet many organizations can't answer basic questions about what they own, what they spend, or whether they're getting value. These strategies focus on visibility and optimization.
Treat IT spending as an investment portfolio that requires active management, not a fixed cost to endure. Turn IT from a cost center into a strategic advantage through disciplined analysis and continuous improvement.
16. IT Asset Inventory and Optimization
$2.3 million. That's how much one client was wasting annually on unused software licenses. They had no idea.
Shadow IT, unused licenses, and forgotten subscriptions drain budgets silently. An inventory strategy implements discovery tools that automatically identify hardware, software, and cloud services across your environment.
Build a single source of truth for what you own, where it lives, who uses it, and what it costs. Analyze usage data to identify underutilized assets. Consolidate redundant tools. Reclaim licenses from inactive users.
Integrate data from multiple sources (procurement systems, software asset management tools, cloud billing). Establish processes to keep inventory current. Schedule regular optimization reviews.
Organizations building comprehensive visibility into their technology estate should implement a robust IT asset management process that tracks assets from procurement through disposal while optimizing utilization and costs.
Most organizations discover they're paying for 30-40% more software licenses than they actually need. Employees change roles, leave the company, or switch to different tools, but the licenses remain assigned and billed monthly.
Your asset inventory is a lie. It's always a lie. Make it less of a lie.
The real value of asset inventory isn't knowing what you have. It's knowing what you can get rid of. Addition is easy. Subtraction is where the savings live.
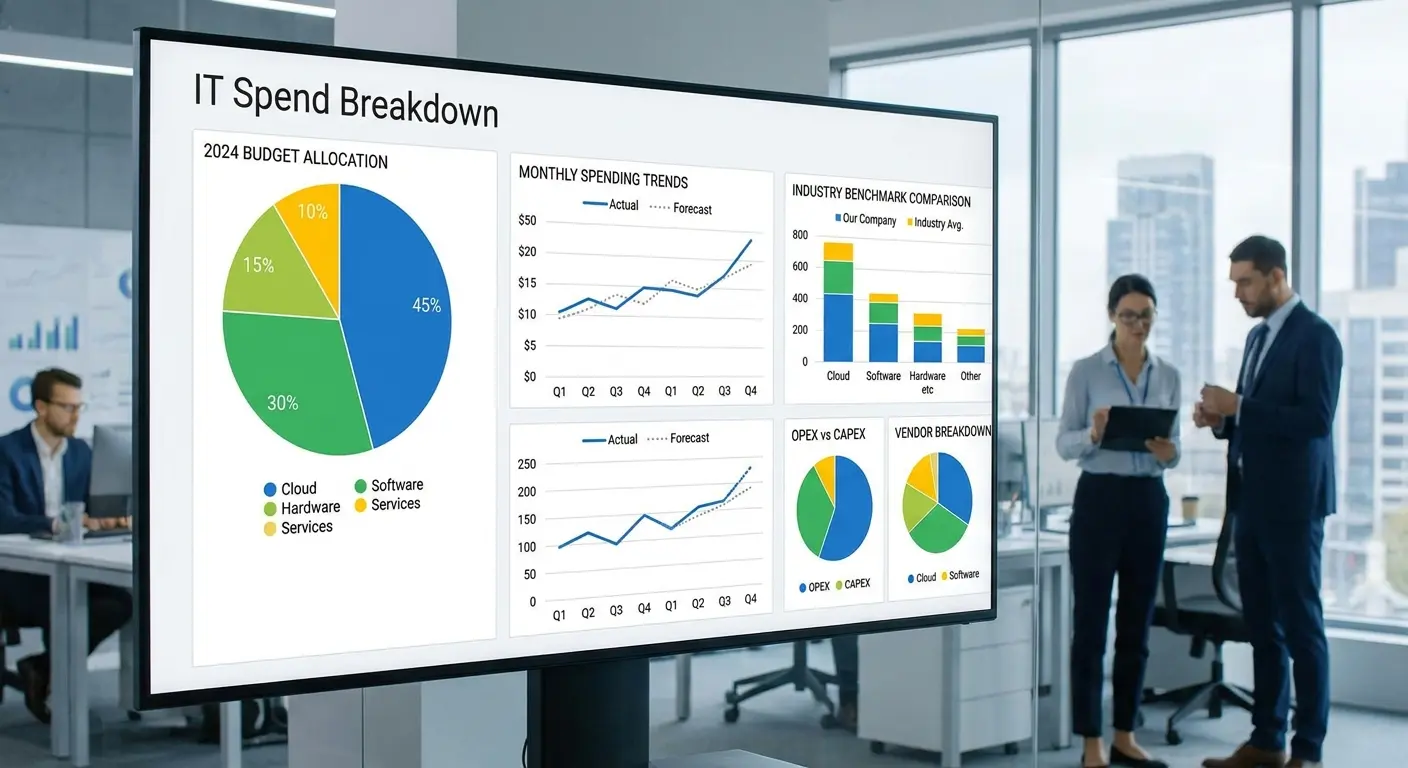
17. Technology Spend Analysis
A CFO once told me, "We spend $12 million on IT and I have no idea what we're getting for it." That conversation led to the spend analysis project that found $3.2M in waste. The CFO became IT's biggest champion after that.
Most organizations know their total IT budget but can't break it down meaningfully by category, business unit, or project. Spend analysis strategies implement financial management tools that categorize every dollar, track spending against budgets in real-time, and forecast future costs based on growth assumptions.
Move from annual budgeting exercises to continuous financial management with visibility into trends and anomalies. Reveal where you're overspending relative to benchmarks, which investments deliver measurable returns, and where you have opportunities to shift spending from operations to innovation.
Effective spend management requires understanding IT cost optimization strategies that reduce waste while maintaining service quality and supporting business objectives.
Granular visibility matters because aggregate numbers hide problems. Your total cloud spend might look reasonable while individual business units run unchecked experiments that rack up massive bills.
Be honest: do you know what your company spent on IT last month? Not the budget. The actual spend? If not, you don't have spend management, you have spend hope.
18. Vendor Consolidation Initiative
Every vendor relationship carries overhead. Contracts to manage. Invoices to process. Integrations to maintain. Relationships to nurture.
Consolidation strategies identify opportunities to reduce vendor count by selecting partners with broader capabilities or better integration.
Map your current vendor ecosystem. Identify overlapping or redundant services. Evaluate enterprise agreements that bundle multiple capabilities. Negotiate better terms with strategic partners.
Balance consolidation benefits (simplified management, volume discounts, better support) against risks (vendor lock-in, reduced redundancy). You're not consolidating for its own sake but to reduce complexity and improve leverage.
The counter-argument to vendor consolidation: you're putting all your eggs in one basket. Fair point. That's why I said 50-75 strategic partners, not 5. You need some redundancy.
This pays dividends beyond cost savings. Fewer vendors means fewer security reviews, simpler compliance audits, and reduced training overhead for your team.
Nine times out of ten, organizations run 200-300 active vendor relationships when 50-75 strategic partnerships would deliver better outcomes at lower cost and complexity.
Vendor consolidation is almost always worth it. Yes, you lose some redundancy. The operational simplicity is worth that risk 90% of the time. For the hardware you buy and ship, getting procurement right at scale matters just as much, as we detail in the state of global IT hardware procurement.
19. Service Level Agreement (SLA) Redesign
Traditional SLAs measure uptime percentages that don't reflect actual business impact. Redesigning SLAs involves shifting from purely technical metrics to business outcome measures, establishing tiered support based on criticality, and implementing financial penalties or credits when commitments aren't met.
Collaborate with business stakeholders to understand what actually matters (transaction processing times, customer-facing system availability, data freshness). Map technical capabilities to these outcomes. Negotiate agreements that align vendor incentives with your success.
The redesign often reveals gaps where you're paying for guarantees that don't cover your actual needs.
Organizations redesigning service agreements should leverage SLA tracking and management tools that provide visibility into vendor performance and automate escalation when commitments are missed.
A vendor might deliver 99.95% uptime while your business suffers because the 0.05% downtime happened during peak sales periods. Traditional SLAs don't account for when failures occur, only how often.
What's the point of 99.9% uptime if your users can't actually get work done?
Final Thoughts
Let's be honest about what happens next.
You're going to close this tab. Maybe you'll Slack it to your team. Someone will say "great article" and then everyone will go back to fighting fires.
I've seen this movie before. IT strategies die in PowerPoint because nobody wants to do the hard work of actually implementing them.
So here's my challenge: Don't do all 19 of these. Pick THREE. The three that are currently causing you the most pain or bleeding the most money.
Where Should You Actually Start?
Don't try to do all 19 at once. You'll fail. Here's how to prioritize:
If you're hemorrhaging money: Start with Asset Inventory and Spend Analysis. Find the waste first, then fund everything else from savings.
If you've had a security incident: Incident Response Playbook and Endpoint Hardening immediately. You're in crisis mode.
If your employees are revolting: Self-Service Portal and Device Lifecycle. Fix the daily pain points.
If you're building from scratch: Zero-Trust, Cloud-First, and API-Led form your foundation. Get these right or regret it forever.
If you're just trying to keep the lights on: Asset visibility and device management prevent fires before they start.
Startups under 100 people: You don't need half of this. Focus on Remote Work Enablement, Device Lifecycle, and Asset Inventory. Everything else can wait.
Block time next week. Not to plan. Not to strategize. To START. Book the vendor demo. Run the asset audit. Deploy the first pilot.
The companies that win at IT strategy aren't the ones with the prettiest frameworks. They're the ones that ship, measure, adjust, and ship again.
Everything I've written here is useless if you don't execute.
So: what are your three? And what are you doing about them Monday morning? For a real example of executing at scale, see how Upwork centralized device logistics across 30+ countries with GroWrk.
More IT strategy examples and how to use them
The IT strategy examples below complement the 19 above by covering the fundamentals: what an IT strategy is, the main types, and named companies whose IT strategy examples show these ideas in action. The most useful IT strategy examples are the ones you can adapt, so treat these IT strategy examples as building blocks and start with the IT strategy examples that map to your biggest priorities. Reviewed together, these IT strategy examples turn a list of tactics into a working plan.
Key takeaways
- A solid IT strategy aligns technology initiatives with business goals, fostering innovation, efficiency, and competitive advantage.
- Organizations can employ various IT strategies such as cloud, cybersecurity, and data governance to address specific needs and enhance operational performance.
- Key components of a successful IT strategy include business alignment, resource allocation, IT asset risk management, and a clear technological roadmap.
Understanding IT strategy

An IT strategy is a carefully formulated plan that aligns technology with a company's business goals, ensuring technology projects contribute to broader objectives. Aligning technology with business needs lets companies innovate, enhance efficiency, and stay competitive. Different types of IT strategies cater to various needs, including defensive, offensive, cost leadership, innovation, customer focus, and digital transformation strategies.
Common types of IT strategies
Organizations can employ various IT strategies to achieve business objectives, from managing existing infrastructure to driving digital transformation. Key strategies include Infrastructure Management, Cybersecurity, Cloud, IT Service Management (ITSM), Data Governance, Digital Transformation, and Business Continuity and Disaster Recovery.
1) Infrastructure management strategy

A robust IT infrastructure management strategy ensures IT resources align with organizational goals and optimize performance. Cloud adoption improves efficiency and flexibility, and automation reduces manual tasks so teams can focus on strategic initiatives.
2) Cybersecurity strategy

An effective cybersecurity strategy safeguards data and mitigates risks, measured by reduced breaches and compliance with IT industry regulations. It integrates protective measures, an incident response plan, and ongoing monitoring, while a culture of security awareness helps deter insider threats.
3) Cloud strategy

A cloud strategy prioritizes cloud computing to enhance scalability and speed, improving flexibility, collaboration, and efficiency. Security considerations are integral, and effective implementation can deliver significant cost savings while aligning cloud investments with business objectives.
4) IT Service Management (ITSM) strategy
%20strategy.png?width=600&height=300&name=5.%20IT%20Service%20Management%20(ITSM)%20strategy.png)
An ITSM strategy delivers value through efficient IT services aligned with business needs. Key processes such as incident, change, and problem management ensure effective service delivery, drawing on best practices including ITIL, COBIT, and ISO/IEC 20000.
5) Data governance and management strategy

Data governance ensures data quality and compliance, guiding organizations in managing their data assets. A governance framework provides structured practices that reduce errors and prevent inefficiencies through consistent data use.
6) Digital transformation strategy

A digital transformation strategy leverages digital technology to innovate processes and create new value for customers. Success often involves cross-department collaboration, a clear technology roadmap, and the right technology partners, with regular feedback keeping the effort agile.
7) Business Continuity and Disaster Recovery (BC/DR) strategy
%20strategy.png?width=600&height=300&name=8.%20Business%20Continuity%20and%20Disaster%20Recovery%20(BCDR)%20strategy.png)
A BC/DR strategy ensures organizational resilience and recovery from disruptions. A business continuity strategy of IT asset management maintains critical operations, while a disaster recovery plan focuses on system restoration after an incident.
Real-world IT strategy examples

These real-world IT strategy examples show how named companies apply technology to meet business goals, often through partnerships with technology leaders.
Mayo Clinic's data privacy and AI strategy
Mayo Clinic partnered with Google to build a secure cloud system that boosts data privacy and supports AI research, managing patient data securely while ensuring compliance with privacy regulations.
p>Capital One's cloud transformation
Capital One transitioned to AWS, becoming a cloud-first organization to improve agility, scalability, and customer satisfaction while lowering operational costs.
p>Walmart's blockchain supply chain
Walmart implemented blockchain to improve traceability and transparency in its supply chain, reducing food traceability time from days to seconds.
p>Starbucks and Nike
Starbucks uses AI through its Deep Brew platform to personalize recommendations and automate inventory tasks, while Nike applies AI across customer engagement and supply chain management to predict demand and reduce lead times.
Key components of a successful IT strategy

Key components of an IT strategy include business alignment, IT governance, technology architecture, and resource allocation. Together they frame informed technology investment decisions that align with business goals and improve adaptability to market changes.
Steps to develop an effective IT strategy

A successful IT strategic plan defines goals, assesses current capabilities, engages stakeholders early, outlines strategic actions, provides a roadmap, and tracks performance against clear KPIs.
Benefits of a well-defined IT strategy

A well-defined IT strategy enhances operational efficiency, reduces costs through better resource allocation, and creates competitive advantage by turning technology into higher productivity, stronger customer experience, and measurable business growth.
Frequently Asked Questions
Why is a well-defined IT strategy important for businesses?
A well-defined IT strategy enhances innovation, efficiency, and customer satisfaction, allowing businesses to outperform competitors and position themselves for sustainable success in a rapidly evolving market.
What are some common types of IT strategies?
Common types of IT strategies include Infrastructure Management, Cybersecurity, Cloud, IT Service Management, Data Governance, Digital Transformation, and Business Continuity and Disaster Recovery strategies.
What was Mayo Clinic's goal and strategy regarding data privacy and AI?
Mayo Clinic aimed to enhance data privacy and security while advancing AI research, employing a strategy that included collaboration with Google to develop a secure cloud infrastructure.
How did Capital One transform its operations?
Capital One adopted a cloud-first strategy, migrating to AWS to improve agility, scalability, and customer experience while cutting operational costs.
Keep exploring IT strategy
Related reading: IT strategy template, IT infrastructure management, ITAM vs ITSM, what is IT asset management, IT risk management, and IT compliance.


